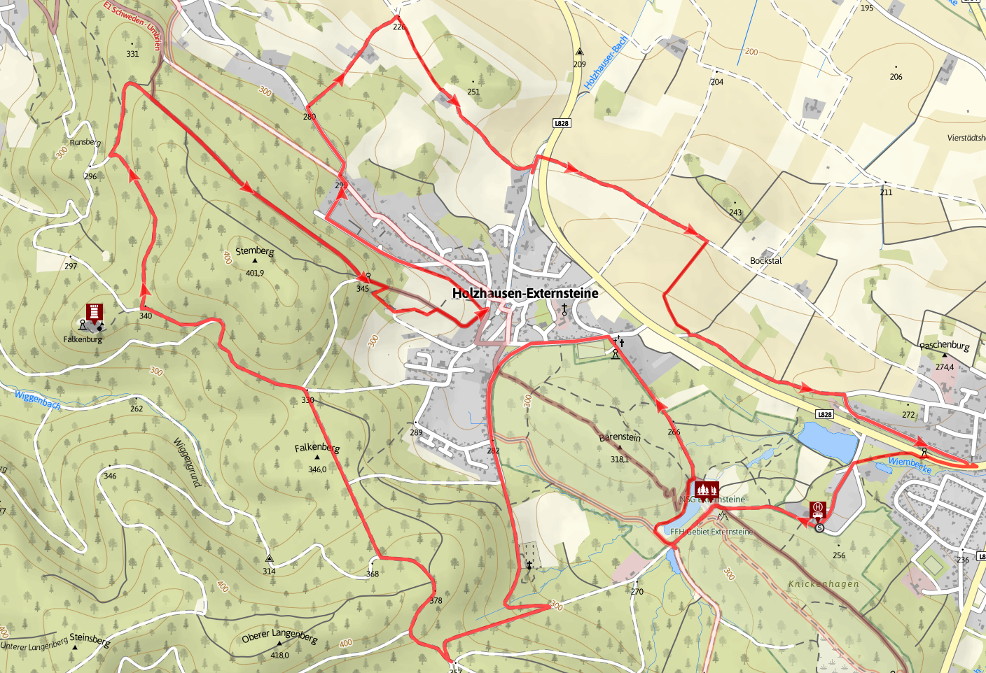
Hermannsdenkmal, Donoper Teich
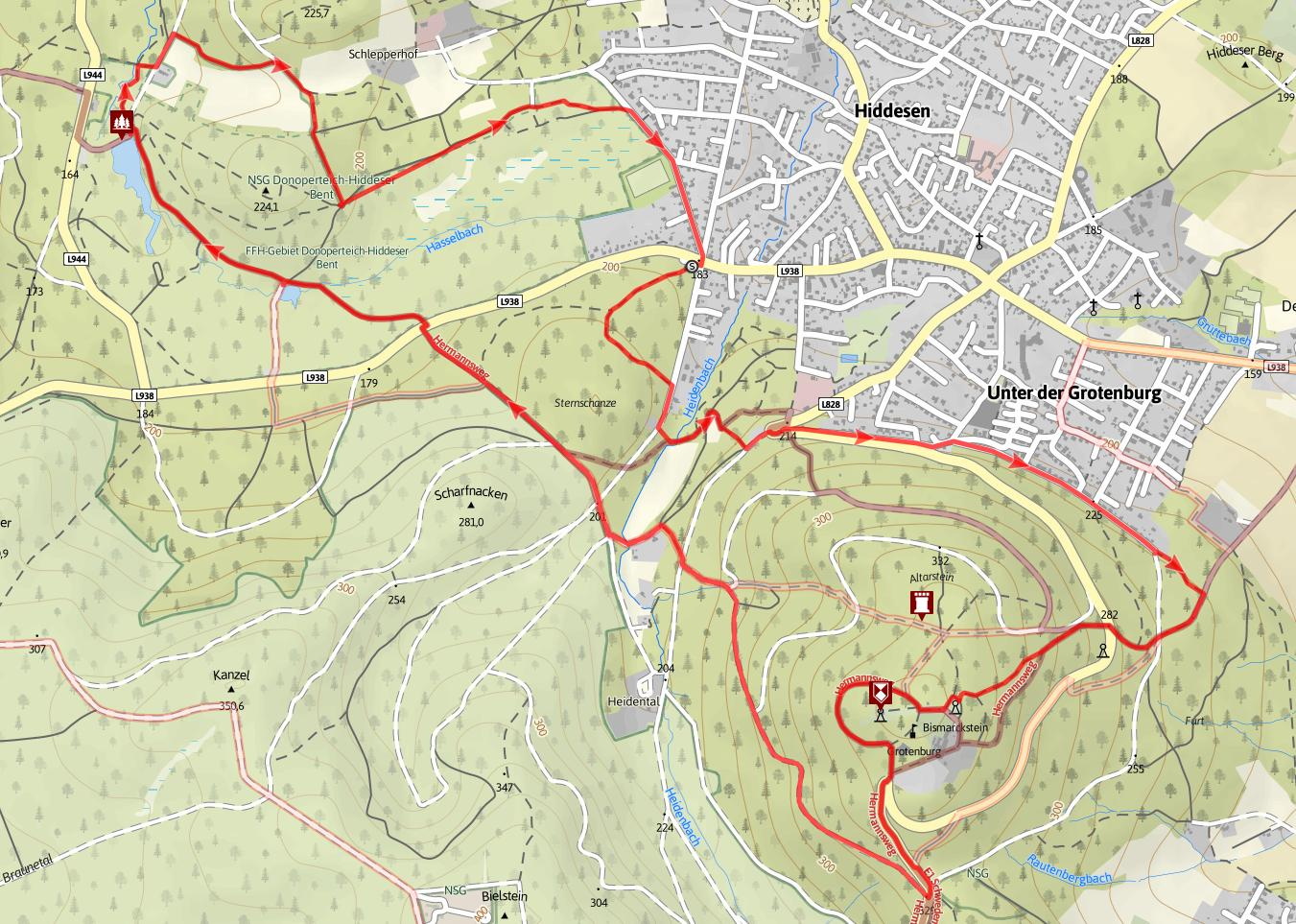
- 12 km around the Hermannsdenkmal and Hiddesen (Detmold)
- moderate climb of 330m
- passes the Donoper Teich (small lake), which looks quite dead to be honest (it’s also fed by a stream of suspiciously brown water)
- passes the Hiddeser Bent, one of the few remaining raised bogs - the trail around the bog is a bit muddy
- we had quite a nice view






The last one is the bog.